IT研究中心
继往开来,创新无限
继往开来,创新无限

2022年12月,在拉斯维加斯举办的2022亚马逊云科技 re:Invent 全球大会完美落幕,这一标志性的技术盛宴再一次给人们留下了无限的想象空间,等待大家在新的一年去持续探索和发掘。
而最让人关注的,应该就是各类新服务了,今年无论是 Adam 还是 Swami 博士的 Keynote 很多篇幅都是和数据相关的新服务和新特性,尤其是 Swami 博士关于数据创新起源的表述以及新的端到端云原生数据战略。
所以,接下来我们将目光切回今天这篇文章关注的对象——数据,更具体地说是众多新发布中占据高位的 Amazon Redshift 云数据仓库。
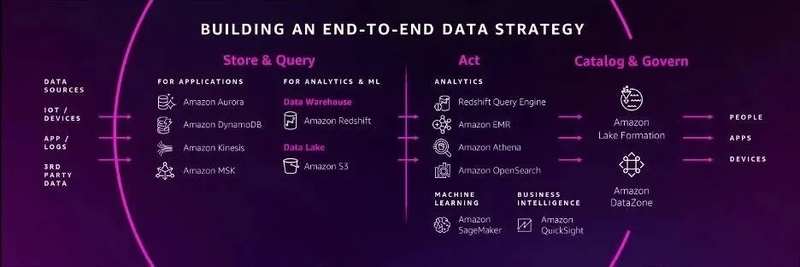
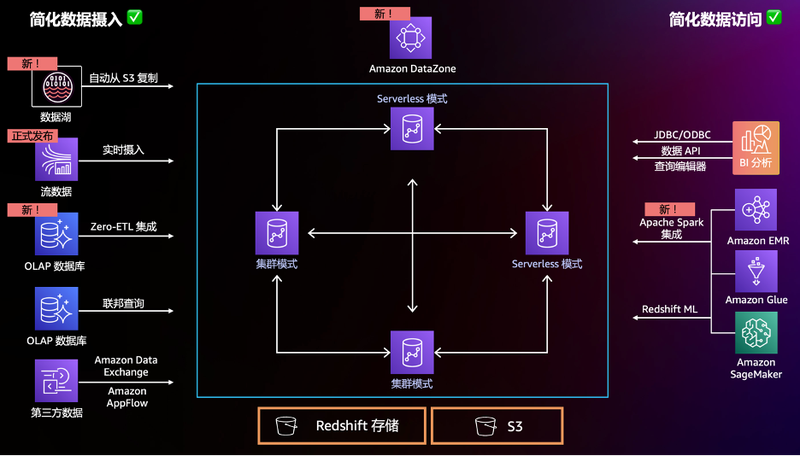
从上面 Swami 博士的图中可以看到,整个战略中 Amazon Redshift 确实处于“核心C位”,在存储、查询和分析中都发挥重要价值,而今年 Redshift 新发布的功能特性也有点多得数不过来,这些功能特性有一个核心目标就是化繁为简。在经过了从0到1的技术突破和从1到100的规模化后,亚马逊云科技正在努力尝试着做从1到0的事情,这里的从1到0是面向客户的,衡量的是客户的复杂任务。即使是从100的手动操作到1的自动化仍然不够,目标是从1到0,消除这些琐碎和不应该困扰的工作,实现像 Serverless 一样的目标,让客户全心投入到业务中去。
接下来,围绕着化繁为简这个目标,本篇文章尝试贴合上面的数据战略通过四个分支来解读下今年 Redshift 这些新发布的功能特性。
1. 简化数据摄入工作,最好是没有
要想数据分析到位,首先要保证有稳定、可靠的数据摄入通道,来实现端到端的第一环(其实还有第零环,是业务在数据源侧的规划),而这一块也是大部分数据工程中遇到最头疼的问题之一。首先,数据源就包含很多种,最常见的数据源包括关系型数据库、数据湖和实时的流数据。其次,不管是手动还是自动的 ETL 流水线,都需要专业的数据工程团队来构建和维护,并且经常要处理或介入数据结构的变更等情况。这次,Redshift 连发多个功能特性来帮助客户解决或者消除这类问题。
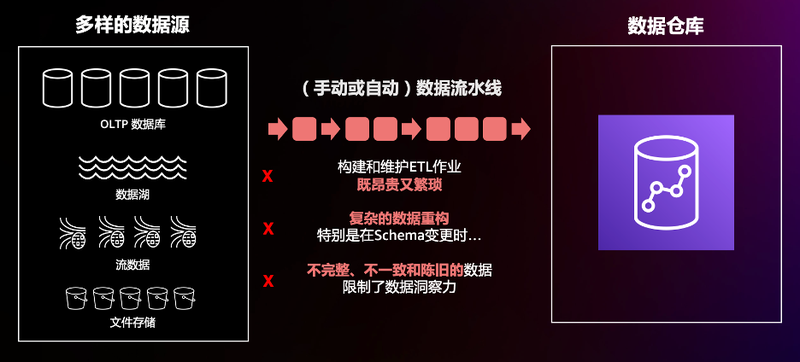
首先是最常见的关系型数据库,也就是经典的 OLTP 向 OLAP 的数据传递。如果是为了更快或者更实时地获取线上业务的事务数据来做分析,通常可以通过开启数据库的 binlog 来捕捉 CDC 变更,然后再使用解析 CDC 的工具如 Amazon DMS、Debezium 等来实现,这些都需要客户进行不断地监控、配置和优化。此外,不同的数据库和数据表可能会有不同的需求,这样就再加倍了数量级的维护成本。
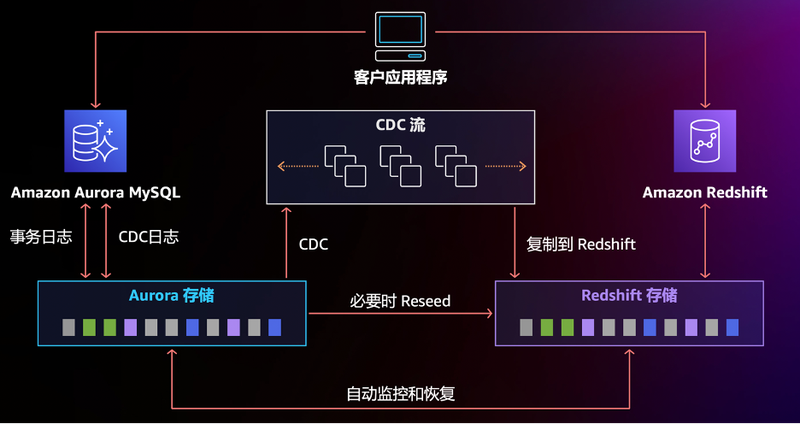
相信大家对 Redshift 印象最深的一个功能就是 Zero ETL,帮助客户完成从1到0的过程!Redshift 通过与 Amazon Aurora 数据库深度集成,在事务型数据写入 Aurora 后,数据在底层被持续地复制到 Redshift,完成行式数据存储到列式数据存储的转换,彻底消除了自己构建和维护复杂数据管道的工作。没有 Hybrid OLTP 和 OLAP,仍然是熟悉的 Amazon Purpose-Build(Aurora 还是 Aurora,Redshift 还是 Redshift)各司其职解决最实际的问题。同时,客户的应用程序架构保持不变,读写端点指向 Aurora,分析端点指向 Redshift,但是底层已经不再是一大串接一大串的数据抽取、转换和加载,直接无缝衔接并且达到近实时的效果。目前关于 Redshift Zero ETL 的信息仍然有限,了解到性能可以达到“几秒钟内数据就被复制到数据仓库中”,大家后续可以持续跟进,相信亚马逊云科技还会持续推出更多的关系型数据库类型和版本的支持,帮助客户实现 ETL 自由!

然后是数据湖 S3,Redshift 开始支持从 S3 数据湖中自动复制,手动挡升级自动挡。之前,如果想要拷贝数据都需要手动或者定时执行 COPY 命令,现在 Redshift 新添加了 COPY JOB 命令自动检测指定路径的新文件,跳过已经加载完毕的旧文件。以前编写的定时任务脚本可以退役了,而且再也不用担心手抖重复执行,生活变得更美好了。
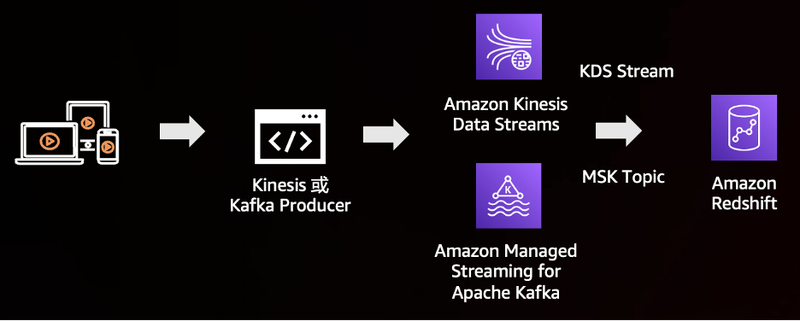
如果业务需求是实时的,那么通过 S3 作为 Staging 存储再 COPY 的方式就跟不上节奏了,所以,流数据也要拿下。re:Invent 之前,Redshift 流式摄入已经开始支持 Amazon Kinesis Data Streams,这次发布更是添加了 Amazon Managed Streaming for Apache Kafka(MSK),同时流式摄入也正式推出,告别预览。从上面的图中可以看出,流式摄入合并了数据消费的过程,直接在 Redshift 中实现并持续加载到数据仓库。在 Redshift 中,流式摄入是通过物化视图的方式实现的(查找官方文档是在物化视图章节),用户还可以在这个物化视图基础上再配合其他数据叠加物化视图提高查询效率。另外,别忘了还可以给流式摄入开启自动刷新功能。从此,客户可以更简单地完成实时数据分析,包括 IoT 物联网设备、点击流、应用程序监控、欺诈检测和游戏实时排行榜等。
以上,Redshift 简化了各种最经典的数据源 ETL 方式,数据坐等分析。
2. 更多数据分析的利器,来点火花
数据已经妥妥地进到了数据仓库的碗里来,接下来就请开始它的表演了。此时,数据工程师表示 Redshift SQL 很好,但是还有些更复杂业务数据逻辑更适合通过代码的方式进行操作和处理(而不是通过 UDF)。开源大数据生态体系下有非常丰富的软件供组织采用了,其中功能完善、发展稳定的 Apache Spark 往往是一个优先的选择。在亚马逊云科技平台上使用 Spark 并不复杂,有托管服务 EMR 和 Glue 保驾护航,还有新发布的 Amazon Athena for Apache Spark 可以极速启动交互。但是,说到 Spark 和 Redshift 之间进行数据分析还是需要折腾一下的,或者是通过将 Redshift 中的数据导出到 S3 中,或者是使用各种第三方的 Spark 连接器,前者需要多走一步浪费时间和资源,后者没有多少人维护不说,性能和安全性都令人堪忧。因此,Amazon Redshift integration for Apache Spark 应运而生。
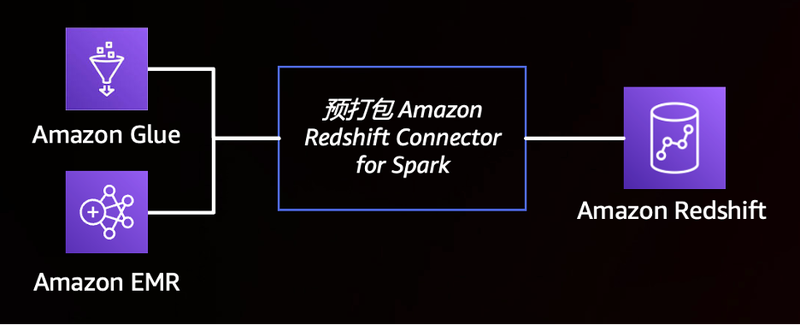
这个内置集成模式基于一个之前的开源项目,提升了性能和安全性,相信后续亚马逊云科技仍将继续跟进这个开源项目,并将各种升级改造的好东西贡献给社区。目前,EMR、EMR on EKS、EMR Serverless 和 Glue (限定版本)都预置了打包好的连接器和 JDBC 驱动程序,客户完全可以直接开始编写代码(有爱好者迫不及待连夜在 EMR Studio 中使用 EMR on EKS 完成了对 Redshift Serverless 和集群模式的交互式读写测试,体验极佳),对 Redshift 中的数据进行处理。如果客户的数据分析工作负载以 Spark 为主,也可以通过 Spark 统一对各种数据源的分析。包都打好了,快来试试看吧!
3. 更优雅的数据分享,从 Redshift 到 Redshifts
Redshift 用户通常都拥有不止一个集群(或者 Serverless),那它们之间是怎么进行有效的协作呢?答案是 Data Sharing。Redshift 的 Data Sharing 功能从推出到现在已经快一年半时间了,客户将它用在组织内实现不同的数据架构,如 Data Mesh 等。Data Sharing 功能使用起来非常方便,并且支持跨账号、跨区域以及跨集群和 Serverless 模式,这过程中数据并没有任何移动,是通过 Zero Copy 的方式实现(又一个从1到0的故事)。
一个生产者对应一个消费者的情况非常容易理解并进行管理,但是企业面临的往往是数十个甚至成百上千的不同数据之间需要相互共享,记录并维护这些相互交错的数据共享就变得十分困难,这时候企业尤其需要一个能集中管理跨不同组织和部门的数据共享权限工具,Lake Formation 再次出场。
Lake Formation 服务的目标就是为了简化数据的集中管理,此前 Lake Formation 基于独特的集中权限模型(数据目录资源和基于标签的授权模式),可以对数据湖的数据进行细粒度的集中访问控制(数据表、行、列等),并且可以很方便地与其他服务如 Athena、QuickSight,当然还有 Redshift 的集成。这一次,Lake Formation 和 Redshift 的集成再一次加强了,提供了集中管理 Redshift Data Sharing 的能力,客户可以使用统一的 Lake Formation 集中查看和管理 Redshift Data Sharing,也可以让数据消费者发现和使用这些 Redshift Data Sharing,并继续沿用经过验证的理细粒度权限机制,保障数据使用的安全性。
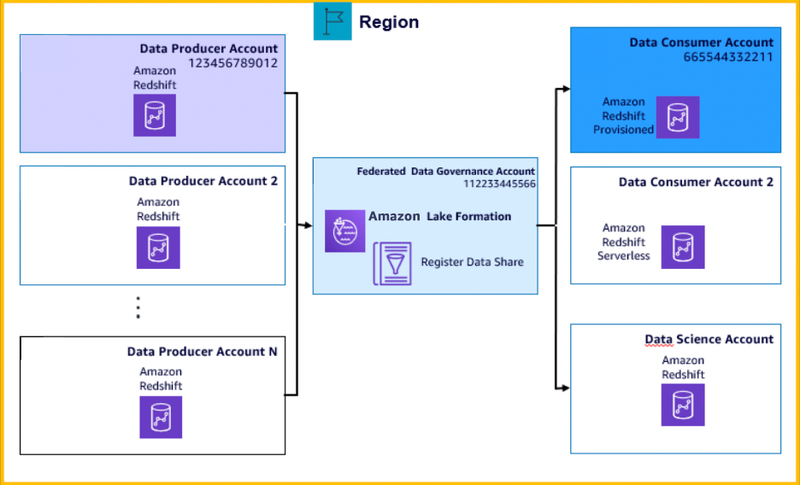
另外,可以根据自己的实际情况,使用 Lake Formation 集中地、安全地管理 Redshift 的大规模数据共享,或许用来构建按需自助使用的、面向领域的、数据即服务的数据架构。
Amazon DataZone 是数据治理方向的一大惊喜。即使有 Lake Formation 带飞,企业中的数据使用者仍然很难找到合适的业务数据,尤其是数据还分散在不同的国家、地区、部分以及各种数据账户中。即使数据使用方找到数据,往往也不了解其中数据的真实含义,需要自己对其进行一系列的摸索,当然,这些都是通过了数据访问控制的难关之后。
数据工程师、数据科学家和数据分析师如何能一起愉快地协作,而不是各个团队做着重复的技术工作,没有带出真实的业务价值输出,这始终是一个企业需要不断思考的问题。Amazon DataZone 给出了一个选项,目标是打通业务数据通道,实现从一开始就能反映业务领域属性的数据架构设计,再配合发布/订阅和事件驱动的模式,一切都是为了简化数据的使用,让数据发挥真正的价值。
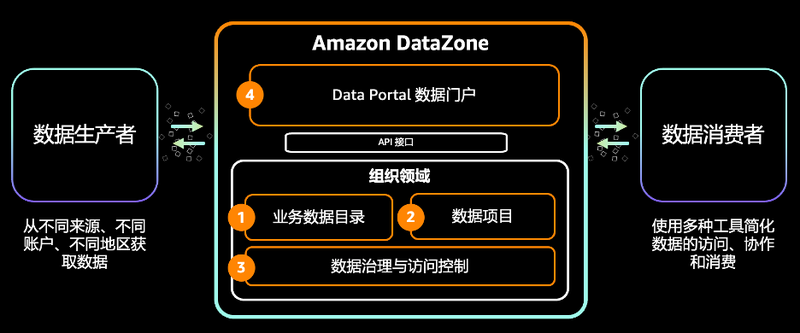
当然,DataZone 和本文主角 Redshift 的集成是无缝衔接的,Redshift 数仓既可以是数据生产者也可以是数据消费者。
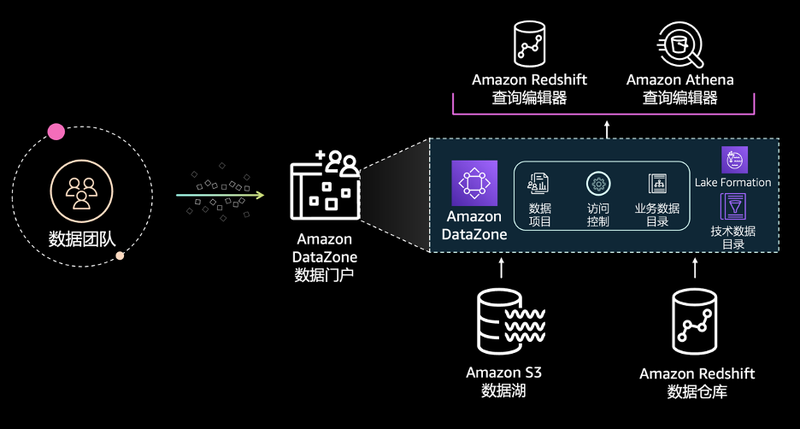
4. 稳定、可靠、合规,居家旅行必备
上述强大的功能全速推进着 Redshift 向前发展,但同时它也需要一个稳定的基座。今年 re:Invent 发布的其他几项更新同样发挥着重要作用。
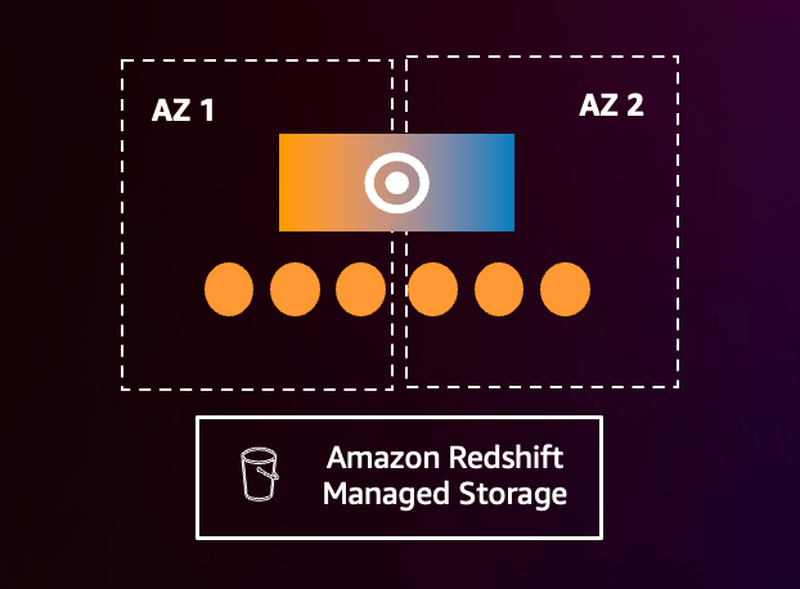
首先是多 AZ 部署(没错,Redshift 原来是单 AZ 模式,但是不用担心,RA3 节点类型集群的数据是持久化在 S3 中的),像其他多 AZ 部署服务一样(例如 RDS),客户可以选在多个可用区部署 Redshift 实现提高可用性。多 AZ 部署通过自动恢复的能力来缩短恢复时间,特别适用于关键的业务分析场景,可以保证RPO =0、RTO <1分钟的数据恢复。
数据备份集中管理服务 Amazon Backup 新补充了对 Redshift 的支持,可以集中地管理备份策略,进一步保护 Redshift 的数据。另外,对于许多国内出海的用户,他们尤其需要关注 GDPR 等隐私法规,所以新功能动态数据屏蔽千万不能错过,它可以用来保护 Redshift 中的敏感数据信息,并且在不用为不同用户创建不同数据拷贝的前提下完成。
小结
以上即是亚马逊云科技2022 re:Invent 全球大会中关于 Redshift 新发布的功能特性的解读,想知道 Redshift 到底是不是真的像宣传的这样,从今天就开始使用吧。
——转载自亚马逊云科技微信公众号2022年12月23日发布文章
